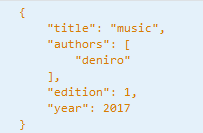
JavaScript 的正则表达式借鉴自 Perl。
正则表达式是一种语法规范,它能够对字符串中的信息进行查找、替换与提取操作。JavaScript 的正则表达式比等效的字符串处理有着显著的性能优势。
正则表达式起源于对形式语言的数学研究,Ken Thompson 写出了一个切实可行的模式匹配器,它能被嵌入到编程语言中。
JavaScript 正则表达式的语法对 Perl 进行了改进与扩张。但它的书写规则非常复杂,所以只有对正则表达式有着透彻的理解,才能写好它。为了缓解这个问题,这里对它的规则进行了简化,尽量减少出错的可能。这是值得的。
正则表达式的缺点很明显:它的所有的部分都被紧密地排列在一起,所以“很难看”。但它还是被广泛地应用着。
1 示例
这里,我们写一个用于匹配 URL 的正则表达式:
var parse_url = /^(?:([A-Za-z]+):)?(/{0,3})([0-9.-A-Za-z]+)(?::(d+))?(?:/([^?#]*))?(?:?([^#]*))?(?:#(.*))?$/;
var url = "http://www.ora.com:80/goodparts?q#fragment";
调用 parse_url.exec() 方法后,会返回一个数组,它包含从 URL 中提取出来的字符串片段:
var result = parse_url.exec(url);
var names = ['url','scheme','slash','host','port','path','query','hash'];
var blanks = ' ';
var i;
for (i = 0; i < names.length; i += 1) {
console.log(names[i] + ':' + blanks.substring(names[i].length),result[i]);
}

现在我们来分解 parse_url 的各个部分:
^ 字符表示这个字符串的开始部分,只匹配那些从开头就像 URL 的字符串:
^(?:([A-Za-z]+):)?
这个因子匹配一个协议名,当且仅当它后面跟随一个 : 时才匹配。(?:...) 表示一个非捕获型的分组。后缀 ? 表示重复 0 次或 1 次。(...) 表示一个捕获型的分组。它会复制所匹配的文本,然后放到 result 数组中。每个捕获型分组都会被指定一个编号,第一个捕获型分组的编号是 1,其它以此类推。[...] 表示一个字符类,A-Za-z 包含 26 个大写字母和 26 个小写字母。连字符 - 表示范围从 A 到 Z。后缀 + 表示会匹配 1 次或多次。
(/{0,3})
这个因子是捕获型分组。/ 表示匹配斜杠。它使用反斜杠进行转义。后缀 {0,3} 表示 / 会被匹配 0 次,或 1 ~ 3 次。
([0-9.-A-Za-z]+)
这个因子是捕获型分组。它匹配一个主机名,是由一个或多个数字、字母以及 . 或 - 字符组成的。- 是为了与表示范围的连字符区分开来。
(?::(d+))?
这个因子是非捕获型分组 。它匹配端口号,是由一个或多个数字组成的序列。d 表示一个数字字符。
(?:/([^?#]*))?
这也是一个非捕获型分组 。它以 / 开始。[^?#] 以一个 ^ 开始,表示匹配除了 ? 和 # 之外的所有字符。* 表示会被匹配 0 次或多次。
注意:这里的处理不严谨的,因为它只排除了 ? 和 # ,而没有考虑行结束符、控制字符等其他不应该在此被匹配。这会存在某些恶意文本会被渗透进来的风险,但写这种不严谨的正则表达式显然容易的多。
(?:?([^#]*))?
这还是一个非捕获型分组 。它内部包含一个捕获型分组,这个分组包含 0 个或多个非 # 字符。
(?:#(.*))?
最后一个可选分组是以 # 开始的,它会匹配除行结束符之外的所有字符。
$
表示这个字符串的结束。
建议尽量保持正则表达式的短小精悍。因为这样才能更容易地修改它们,而且嵌套的正则表达式可能导致恶劣的性能问题,所以简单是最好的策略。
现在来看看另一个例子:一个匹配数字的正则表达式,一个数字可能是由一个整数加上一个可选的负号、一个可选的小数部分和一个可选的指数部分组成:
/**
* 匹配数字
*/
var parse_number = /^-?d+(?:.d*)?(?:e[+-]?d+)?$/i;
var test = function (num) {
console.log(parse_number.test(num));
};
test('1');//true
test('number');//false
test('98.6');//true'
test('23.2138.23');//false
test('123.2E-38');//true
test('123.2D-38');//false
现在我们来分解这个正则表达式:
/^ $/i
我们使用 ^ 和 $ 来框定这个正则表达式。它们表示对文本中的所有字符都进行匹配。如果省略这些标识,只要字符串中包含一个数字,就会被匹配。如果仅包含 ^,它将匹配以一个数字开头的字符串,如果仅包含 $,它将匹配以一个数字结尾的字符串。
i 标识表示匹配字母时,忽略大小写。数字中可能出现的字母是 e,所以我们希望它既能匹配 e,也能匹配 E。
-?
负号后面的 ? 表示这个负号是可选的。
d+
d 的含义与 [0-9] 一样,它们都是匹配一个数字。后缀 + 匹配一个或多个数字。
(?:.d*)?
(?: …) 表示一个可选的非捕获型分组。子所以使用非捕获型分组,是因为捕获型分组会有性能上的损失。这个分组会匹配 0 个或多个数字的小数点。
(?:e[+-]?d+)?
这也是一个可选的非捕获型分组。它会匹配一个 e/E、一个可选的正负号及一个或多个数字。
2 结构
建议使用正则表达式的字面量来创建 RegExp 对象。

RegExp 可以设置 3 个标识:
标识
含义
g
全局(匹配多次)
i
大小写不敏感(即忽略字符大小写)
m
多行(^ 和 $ 能够匹配行结束符)
这些标识被直接添加在 RegExp 字面量的末尾:
var parse_number = /^-?d+(?:.d*)?(?:e[+-]?d+)?$/i;
另一种创建正则表达式的方法是 RegExp 构造器(不推荐)。它接收一个字符串,然后把它编译为 RegExp 对象。创建这个字符串要小心,因为反斜杠在这里与字面量的含义并不同。通常要双写反斜杠,并对引号进行转义。还是字面量定义方式来的清晰呀O(∩_∩)O~
RegExp 对象的属性:
属性
用法
global
如果标识 g 被使用,则为 true
ignoreCase
如果标识 i 被使用,则为 true
lastIndex
下一次 exec 匹配开始的索引,初始值为 0
multiline
如果标识 m 被使用,则为 true
source
正则表达式的源码(文本形式)
3 正则表达式的元素
3.1 分支

一个 正则表达式的分支包含一个或多个正则表达式序列。这些序列被 | 字符分隔。如果这些序列中的任何一项符合匹配条件,那么这个分支就会被选择。它会按顺序依次匹配这些序列项。所以:
"into".match(/in|int/)
会匹配 in,但不会匹配 int,因为 in 已经成功被匹配了啦O(∩_∩)O~
3.2 序列

一个序列包含一个或多个正则表达式因子,每个因子可以选择是否跟随一个量词,这个量词决定这这个因子被允许出现的次数。如果没有指定量词,那么这个因子只会被匹配一次。
3.3 因子

/ [ ] ( ) { } ? + * | . ^ $
如果需要匹配上面列出的字符,就必须使用 进行转义。
一个未被转义的 . 会匹配除行结束符以外的任何字符。
当 lastIndex 为 0 时,一个未转义的 ^ 会匹配文本的开始。
一个未转义的 $ 将匹配文本的结束。
3.4 转义
因子
说明
f
换页符
n
换行符
r
回车符
u
一个 Unicode 字符表示的十六进制的常量
d
匹配数字,等同于 [0-9]
s
是 Unicode 空白符的不完全子集,等同于 [fnrtu000Bu0020u00A0u2028u2029]
S
与 s 相反
w
等同于 [0-9A-Z_a-z]
W
与 w 相反
b
字边界标识,可惜它是使用 w 去寻找字边界,所以对中文来说完全无用
1
指向分组 1 所捕获到的文本的一个引用,可以利用它进行再次匹配。2 指的是分组 2,以此类推。
3.5 分组
分组有四种。

捕获型
捕获型分组是一个被包围在圆括号中的正则表达式的分支。任何匹配这个分组的字符都会被捕获。每个被捕获的分组都指定了一个数字。第一个捕获的分组是 1,第二个捕获的分组是 2,以此类推。
非捕获型
非捕获型以 (?: 作为前缀。它仅做简单的匹配,但不会捕获所匹配的文本。这会带来微弱的性能优势。非捕获型分组不会干扰捕获型分组的编号。
向前正向匹配
向前正向匹配以 (?= 作为前缀。它类似于非捕获型分组,但在匹配之后,文本会倒回它开始的地方,实际上并不匹配任何字符。这个特性不好。
向前负向匹配
向前负向匹配以 (?! 作为前缀。它类似于非捕获型分组,但只有在匹配失败时才会继续向前匹配。这个特性也不好。
3.6 字符集
正则表达式字符集是一种指定一组字符的便利方式,比如想匹配一个元音字母,那么我们可以用类 [aeiou]。
类提供了两个便利功能:
1. 指定字符范围。
2. 对类求反。如果 [ 后的第一个字符是 ^,那就会排除这些指定的字符。
3.7 字符类中的转义
字符类中的 b 是退格符,其他的转义与正则表达式因子的转义相同。而在字符类中需要被转义的特殊字符有这些:
- / [ ] ^
3.8 量词
正则表达式因子使用量词来决定这个因子应该被匹配的次数。包围在一对花括号中的数字就是应该被匹配的次数。下面是一些例子:
/www/ 等同于 /w{3}/
{3,6} 匹配 3,4,5 或 6 次
{3,} 匹配 3 次或更多

? 相当于 {0,1}
* 相当于 {0,}
+ 相当于 {1,}
如果只有一个量词,则趋向于贪婪性匹配,即匹配尽可能多的文本直到上限。如果量词后加了 ?,则表示趋向于进行非贪婪性匹配,即只匹配必要的文本。建议使用贪婪性匹配。