CSV是英文Comma Separate Values(逗号分隔值)的缩写,顾名思义,文档的内容是由 “,” 分隔的一列列的数据构成的。CSV文档是一种编辑方便,可视化效果极佳的数据存储方式。而Python中有着非常强大的库可以处理这种文档,所以,如果你经常用Python处理数据的话,CSV文档当然是一种简单快捷的轻量级选择。下面我将以一个数据处理的例子入手,展现CSV文档的创建和编辑,以及Python是如何对CSV文档读写的。
CSV文档的创建和编辑
1. 良好的Excel交互
(1) Excel创建CSV
说到CSV文档,大家可能不熟悉,不过Excel想必没有人不知道,我们经常使用Excel负责数据的存储,编辑以及轻量级的计算。而CSV文档最大的优点就是能和Excel进行方便的交互,我们可以很方便地通过Excel创建、查看以及编辑CSV文档。
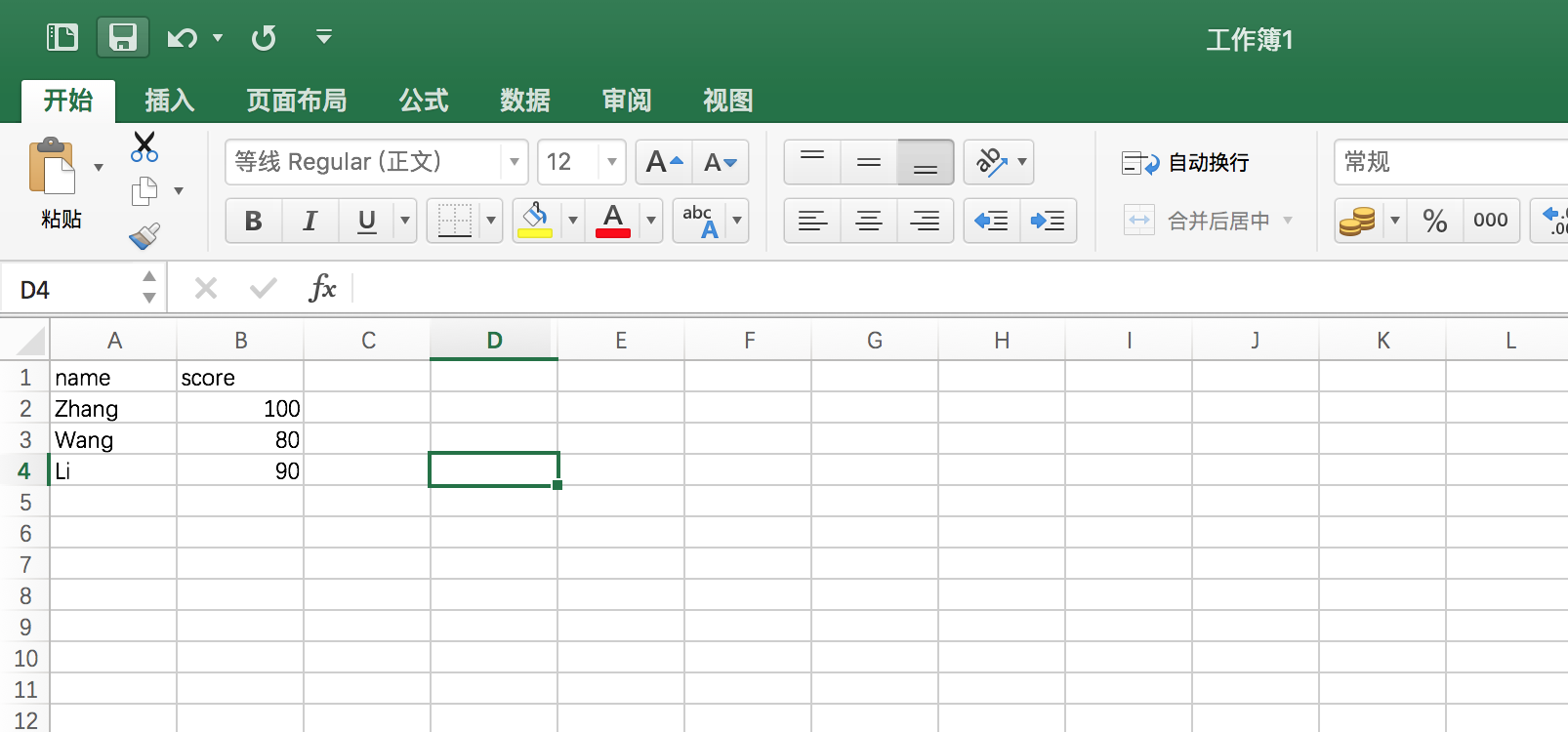
在Excel中编辑完数据后,保存文件的时候,会出现一种文件格式,就是 .csv ,如图:

然后现在点击保存,会发现“文件格式”的选项中有“逗号分隔值(.csv)”:

我们选择文件格式为.csv存储,这样,就通过Excel成功创建了一个CSV文档。
(2) 文本访问和编辑CSV
如果现在我们将刚才创建好的CSV文档直接双击点开,他会默认由Excel打开,依旧和上边相同,用Excel可以很方便的编辑,修改数据,这里不再赘述。我要说的是CSV文档也可以以文本的形式展现出来,比如,我现在把刚才保存的CSV文档用Sublime(你用txt也行)打开,展示如下:

这我们就非常直观地明白为什么叫“逗号分隔值”了,数据之间是由 “,” 分隔开的,且格式非常规范,没有多余的空格,空行等。
这里多说一句:很多mac用户会发现自己的Excel保存的CSV文档并不是以 “,” 分隔的,这里面的原因恕我见识浅薄,具体也不太清楚,大概是编码的问题,一种解决方法是讲mac系统偏好中的设置改成不说汉语的其他地区就可以了(不知道有没有更专业的方法)。
一样的,我们也可以通过文本的形式修改这些数据,然后保存即可,若再用Excel打开,则会显示修改后的结果。这里就不演示了。
同理,除了可以通过Excel创建CSV文档,也可以用通过把其他格式的文档转换成.csv的后缀,也一样可以创建CSV。比如,使用sublime或者Notepad++编辑内容,然后保存为csv格式。但是尽量不要使用类似于Word或者Mac自带的文本编辑器这些,他会把一些自身文件的内容也加进CSV文档,导致文档“不纯净”。
总结一下上边说的,CSV文档是一种可以通过Excel以及普通的文本编辑器创建,访问,编辑的文档。
Python读写CSV文档
上边的文档创建好之后,我们就可以将CSV文档所存储的数据导入Python做处理了。和文本文件一样,Python也可以对CSV文档写入内容,重新编辑。
1. Python读取CSV文档
Python的库csv就是处理CSV文档的一个非常强大的库,我们要处理CSV文档,必须先导入它。
代码如下:
import csv
# 读取csv至字典
csvFile = open("instance.csv","r")
reader = csv.reader(csvFile)
# 建立空字典
result = {}
for item in reader:
# 忽略第一行
if reader.line_num == 1:
continue
result[item[0]] = item[1]
csvFile.close()
print(result)
首先,跟文本文件一样,需要 open() 函数将CSV文档打开,我在此将打开方式定义为只读。然后通过 csv.reader() 函数建立一个读入数据的对象,我起名为reader。
既然刚才我建立的数据是个一对一的关系型数据,那索性就通过字典这种结构完成数据的读取,所以,建立了一个空字典result(后面会讲csv自带的将CSV文档读取为字典的函数)
reader对象其实就是由CSV文档的多行数据构成的,每行数据会有一个属性:line_num表示行数,显然,刚才的数据第一行”name,score”只是数据说明,我们忽略掉。
如果用for循环迭代访问reader,我们会发现,每一行都是一个列表,列表的每个元素就是CSV文档的每一行中 “,” 分隔开的数据。比如:
import csv
csvFile = open("instance.csv","r")
reader = csv.reader(csvFile)
for item in reader:
print(item) # >>> ['name','score']
# >>> ['Zhang','100']
# >>> ['Wang','80']
# >>> ['Li','90']
其实,当然也可以按文本文件那种直接遍历文档对象的方式,不过得到的就是字符串,而不是每一行对应元素构成的列表,显然,对于处理数据而言,读取成列表会更方便,那直接遍历文档对象(这里的csvFile)就是没有必要的了。
所以,我们通过第一段代码,就可以将CSV文档中出了第一行之外的数据读入一个Python字典了。
2. Python写入CSV文档
(1)直接写入
当然也可以将数据写入CSV文档,我们可以将数据以列表的形式写入:
import csv
# 文件头,一般就是数据名
fileHeader = ["name","score"]
# 假设我们要写入的是以下两行数据
d1 = ["Wang","100"]
d2 = ["Li","80"]
# 写入数据
csvFile = open("instance.csv","w")
writer = csv.writer(csvFile)
# 写入的内容都是以列表的形式传入函数
writer.writerow(fileHeader)
writer.writerow(d1)
writer.writerow(d1)
csvFile.close()
当然,每次写完一行之后,会自动换行,所以,写结果就是我们想要的形式:

需要注意的是最后还有一个空行。
当然,像这种写入多行的情况,可以用更方便的函数 writerows(),还是上面的例子,可以把三行写入的代码,换成以下一行。但是传入的参数是一个列表,每个元素代表需要写入的每行数据。得到的结果和上面是一样的。
writer.writerows([fileHeader,d1,d2])
(2)追加
除了直接写入,还能实现追加:还是刚才那个例子,我现在将一行新的数据添加到旧的数据后面,最后写入CSV
import csv
# 新增的数据行,以列表的形式表示
add_info = ["Guo",150]
# 以添加的形式写入csv,跟处理txt文件一样,设定关键字"a",表追加
csvFile = open("instance.csv","a")
# 新建对象writer
writer = csv.writer(csvFile)
# 写入,参数还是列表形式
writer.writerow(add_info)
csvFile.close()
这样,就完成了信息的追加。
3. DictReader提供的方便
像上面这种把一个关系型数据库保存为CSV文档,再用Python读取,处理的情况可以说很常见,大多都是先读成字典的形式,再做相应的计算。所以csv库也就提供了能直接将CSV文档读取为字典的函数:DictReader(),当然,也有相应的 DictWriter()
还是上边的例子:
import csv
csvFile = open("instance.csv","r")
dict_reader = csv.DictReader(csvFile)
for row in dict_reader:
print(row)
输出的结果是这样的:
{'score': '100','name': 'Zhang'}
{'score': '80','name': 'Wang'}
{'score': '90','name': 'Li'}
这个形式就非常清晰明了了,而且还不用费心地写代码将第一行忽略。因为CSV文件第一行,就是(name,score)这一行,能以这种形式输出:
import csv
csvFile = open("instance.csv","r")
dict_reader = csv.DictReader(csvFile)
# 输出第一行,也就是数据名称那一行
print(dict_reader.fieldnames) # >>> ['name','score']
很好理解,fieldnames 是dict_reader的一个属性,表示CSV文档的数据名称。
如果觉得”DictReader”对象不方便对数据处理,还想转换成我们上边那种普通的Python字典对象,也很容易:3行代码即可解决问题
result = {}
for item in dict_reader:
result[item["name"]] = item["score"]
print(result) # >>> {'Wang': '80','Li': '90','Zhang': '100'}
4. DictWriter 以字典形式写入
DictReader可以用来把CSV文件以字典的形式读入,当然还有相对的DictWriter以字典的形式写入内容,比如:
import csv
csvFile = open("instance.csv","w")
# 文件头以列表的形式传入函数,列表的每个元素表示每一列的标识
fileheader = ["name","score"]
dict_writer = csv.DictWriter(csvFile,fileheader)
# 但是如果此时直接写入内容,会导致没有数据名,所以,应先写数据名(也就是我们上面定义的文件头)。
# 写数据名,可以自己写如下代码完成:
dict_writer.writerow(dict(zip(fileheader,fileheader)))
# 之后,按照(属性:数据)的形式,将字典写入CSV文档即可
dict_writer.writerow({"name": "Li","score": "80"})
csvFile.close()
不过,csv也提供了专门的函数 writeheader()来实现添加文件头(数据名),简化开发者的工作,只需要将下面的代码:
dict_writer.writerow(dict(zip(fileheader,fileheader)))
改成这种形式:
dict_writer.writeheader()
上面的两个函数是一样的。之所以这个函数没有任何参数,实际上,是因为在建立对象dict_writer时,已经设定了参数
写入完成。之后,该怎么读,还是怎么读:
import csv
with open("instance.csv","r") as csvFile:
dict_reader = csv.DictReader(csvFile)
for i in dict_reader:
print(i) # >>> {'name': 'Li','score': '80'}