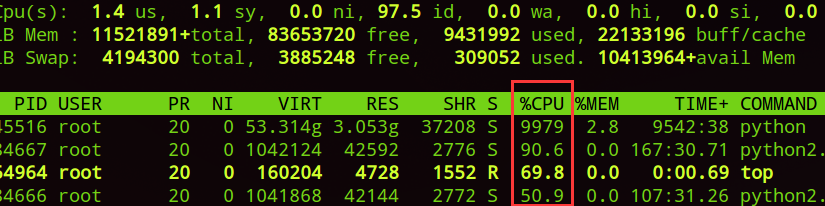
字典是Python中唯一的映射类型。所谓映射,其实就是一种对应关系的表述,在字典中,这种映射关系也被叫做“键值对”。也就是说,字典这种结构的每一个元素,都是由两个对象之间的对应关系构成的,这两个对象,一个叫做“键”(key),另一个叫做“值”(value)。而这种映射关系是一种多对一的关系,一个键所指向的值是唯一的,一个值所却可被多个键指向。一个简单的例子是班上学生某次考试的成绩,学生的学号就可以作为键,而考试分数可以作为值。对于每个学生来说,他的考试分数当然只有一个,而对于某个分数来说,可以有很多学生考的都是这个分数。毋庸置疑,字典的这种对象间对应的特点,为我们处理简单的关系型数据提供了巨大的便捷。
创建和访问
1. 创建
字典的创建方法有三种
(1) 直接赋值
字典和列表,元组的形式不同,他是由 “{}” 括起来的关系构成的,相互映射的元素之间,通过 “:” 连接,映射与映射之间,通过 “,” 分隔。比如,通过直接赋值的方法构造字典,形式如下
a = {} # 建立空字典
b = {"I": 1,"You": 2} # 两对映射:"I" -> 1; "You" -> 2,其中,"I" 与 "You" 为键,1与2为值
(2) dict() 函数
将一个可迭代的对象传递给 dict() 函数,当然这个可迭代对象的每个元素必须是以二元的“对”呈现的。下面,我给出了几个例子
# 传入的参数是一个可迭代的对象,对象的每个元素是二元列表
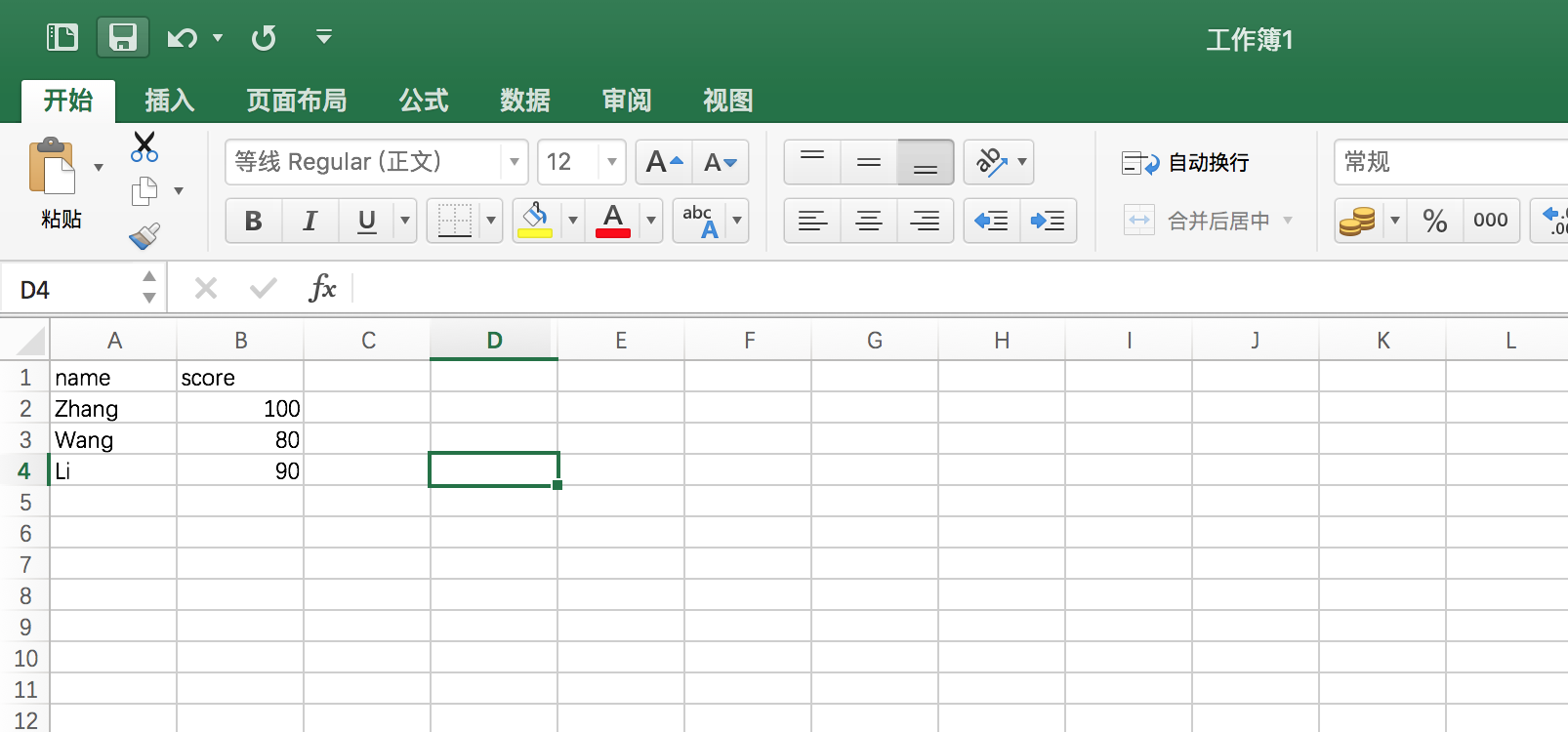
d1 = dict((["name","Wang"],["score",80]))
print(d1) # >>> {"name": "Wang","score": 80}
# 传入列表,列表的每个元素是两个字符构成的字符串
d2 = dict(["ab","cd"])
print(d2) # >>> {'c': 'd','a': 'b'}
d3= dict(zip(["name","score"],["Wang",80]))
print(d3) # >>> {'name': 'Wang','score': 80}
# 甚至可以是这样
d4 = dict(x = 1,y = 2)
print(d4) # >>> {'y': 2,'x': 1}
# 什么都没有,则创建空字典
d5 = dict()
print(d5) # >>> {}
第三个例子当中的 zip() 函数,我在字符串(Python–字符串)以及列表(Python–列表)的讲解中已经详细说过。第四个例子中带入了两个赋值等式,这种多重赋值会被默认为元组()。而赋值的式子也相当于是构成了所谓的“对”。
(3) fromkeys() 函数
对于多个键映射同一个值的情况,可以用fromkeys() 函数很方便的建立一个字典
# 第一个参数为序列,保存构成该字典的键,第二个参数为这些键所对应的值
d1 = {}.fromkeys(("A","B"),100)
print(d1) # >>> {"A": 100,"B": 100}
# 若没有给出值,则默认为None
d2 = {}.fromkeys(["A","B"])
print(d2) # >>> {'A': None,'B': None}
# 即第二个参数也是一个序列,依然将这个序列看做这些键所对应的唯一的值
d3 = {}.fromkeys(("A",[1,2])
print(d3) # >>> {"A": [1,2],"B": [1,2]}
其实从上面最后一个例子也可以看出,字典的值可以是任意类型的对象,包括字典本身,但是字典的键的“规矩”就比较多了,我们后面再仔细谈。
2. 访问
字典的访问,和之前我们将的字符串,列表,元组这些序列类型的结构有比较大的区别。它不存在所谓下标这个说法,而是直接通过键来访问(其实你也可以理解成字典的下标就是每个元素的键)。形式上,是字典后面加个中括号,中括号内为键: dict[key]。所以你看,键在这里多么像列表的下标啊
a = {"A": 100,"B": 80}
print(a["A"]) # >>> 100
而如果我们试图访问一个字典中不存在的键,则会报错
a = {"A": 100,"B": 80}
print(a["C"]) # >>> KeyError: "C"
所以,为了防止程序崩溃,可以在访问字典前,先加上判断语句,若字典中存在我们要访问的键,再访问。至于如何判断字典是否拥有某个键,则要用到成员操作符 in,not in 用法跟之前的字符串,列表,元组是一样的
a = {"A": 100,"B": 80}
print("A" in a) # >>> True
print("C" not in a) # >>> True
成员操作符判断的只是键在字典中是否存在,而有时,我们需要知道的是某个值是否存在。所以,可以借助字典的内建函数 dict.values() 查找值。
a = {"A": 100,"B": 80}
print(100 in a.values()) # >>> True
这个函数后面详说。
当然,也可以通过for循环遍历整个字典
a = {"A": 100,"B": 80}
for key in a: # key 只是一个名字,不管是什么名字,都默认指代键
print(key,a[key]) # "B" 80
# "A" 100
需要注意的是上面的例子中,输出结果的顺序不一定跟我们构建字典时的顺序一致。再强调一遍:字典不存在下标的概念,是没有顺序的。
更新字典
1. 添加和修改
这一点又和序列类型的对象有很大不同了,字典的添加和修改,都可以通过 dict[key] = value 的形式实现
a = {"A": 100,"B": 80}
# 添加映射 ("C": 50)
a["C"] = 50
print(a) # >>> {"A": 100,"B": 80,"C": 50} 还是注意,结果不一定就是这个顺序
# 修改某个键对应的值
a["A"] = 90
print(a) # >>> {"A": 90,"C": 50,"B": 80}
2. 删除映射
pop() 函数可以实现对映射的删除
a = {"A": 100,"B": 80}
# 删除键为 "A" 的映射并返回这个键对应的值
print(a.pop("A")) # >>> 100
# ("A": 100) 已经被删了
print(a) # >>> {"B": 80}
用法跟之前讲的列表的用法一样,不多说了。其实,从 pop() 函数的用法,也会发现字典中键的作用跟列表,字符串这些序列类型的下标非常类似。
内建函数
1. 长度
还是用函数 len() 返回映射的个数
a = {"A": 100,"B": 80}
print(len(a)) # >>> 2
2. 拷贝和清空
(1) clear() 清空
a = {"A": 100,"B": 80}
# 清空字典中所有元素
a.clear()
print(a) # >>> {}
(2) copy() 浅拷贝
a = {"A": 1,"B": 2}
b = a.copy()
b['A'] = 3
print(b) # >>> {'B': 2,'A': 3}
print(a) # >>> {'B': 2,'A': 1} # b变了,a没变
a = {"A": [1,"B": [3,4]}
b = a.copy()
b['A'][0] = 5
print(b) # >>> {'B': [3,4],'A': [5,2]}
print(a) # >>> {'B': [3,2]}
从后一个例子可以看出b变的同时,a也变了。这也就是浅拷贝的含义:拷贝的对象是新的,但内容还是对之前旧的对象的引用。所以,如果值是不可变的类型还好,如果是可变类型,比如列表,做复制操作时,一定要十分小心。
3. 键,值和映射
(1) dict.keys()
a = {"A": 1,"B": 2}
print(a.keys()) # >>> dict_keys(['B','A'])
可见,返回的是一个包含字典中所有键的特殊列表,之所以说是特殊列表,是因为这中类型的列表虽然可迭代访问,却不能按下标访问或者按切片访问
a = {"A": 1,"B": 2}
for i in a.keys():
print(i) # >>> 依次输出A,B
# 这种写法是错误的!
print(a.keys()[0])
(2) dict.values()
与dict.keys() 函数同理
a = {"A": 1,"B": 2}
for i in a.values():
print(i) # >>> 依次输出1,2
(3) dict.items()
返回的是包含键值对的元组列表
a = {"A": 1,"B": 2}
for i in a.items():
print(i) # >>> 依次输出('A',1),('B',2)
以上三个函数都有共通性:生成的对象都不能通过下标或切片访问
4. 拓展
dict.update(dict2)
把字典dict2的内容加到dict当中
a = {"A": 1,"B": 2}
b = {"C": 3}
a.update(b)
print(a) # >>> {"A": 1,"B": 2,"C": 3}
其实还有个很重要的内建函数是 pop(), 不过刚才讲字典的删除时,已经说过了。
字典的排序
和列表的排序一样(Python–列表)通过函数 sorted() 生成一个排好序由键构成的的列表。通过对这个列表的处理,可以衍生出很多排序的用法。想一想字典排序在数据处理中一定是一件非常重要的是事情,比如全班同学的学号和分数构成字典,我们现在要按分数排序,但我总得知道这排好序的分数都对应着哪个同学,否则就是毫无意义的。
根据排序的要求,我们将任务分为两类:按键排序,按值排序。
(1) 按键排序
这也是sorted() 默认的排序模式
data = {1: "Tom",3: "Joe",-1: "Alice"}
sort_data = sorted(data)
print(sort_data) # >>> [-1,1,3]
这样看似乎没什么用,不过略加变化,就能看出效果
data = {1: "Tom",-1: "Alice"}
for key in sorted(data):
print(key,data[key]) # >>> -1 Alice
# >>> 1 Tom
# >>> 3 Joe
当然,也可以按降序排列
data = {1: "Tom",-1: "Alice"}
for key in sorted(data,reverse=True):
print(key,data[key]) # >>> 3 Joe
# >>> 1 Tom
# >>> -1 Alice
需要注意的是上面的例子中,字典data本身并未改变,这个和列表的原理是一样的,不再赘述
(2) 按值排序
按值排序比按键排序要复杂一些,我们需要用到匿名函数 lambda,这个匿名函数的实际作用是将定义好的函数的函数名赋值给 sorted() 函数的参数key,key的作用是确定排序的依据。比如下面这个例子
data = {"Tom": 100,"Alice": 88,"Joe": 90.5}
for i in sorted(data.items(),key=lambda x: x[1],reverse=True):
print(i) # >>> ('Tom',100)
# >>> ('Joe',90.5)
# >>> ('Alice',88)
解释一下,我们已经知道迭代访问 data.items() 返回的是一个个两个元素构成的元组,那么现在可以理解为:我们在对一个由二元元组构成的可迭代对象排序。key现在实际上是指代了一个函数,这个函数的作用是取一个序列的第1位(也就是第二个元素)。而key参数的作用是定义排序的依据。
换句话说, data.items() 是要参与排序的内容,这些内容排序的依据是按 key 所指代的函数–取第1位元素计算得来的。
总结起来的意思就是:对于一个由二元元组组成的可迭代对象,按照每个元组的第2个元素的大小排序。后面的 reverse=True 还是表示降序。
当然,在此用 lambda 匿名函数是因为他十分方便,其实不用匿名函数也是可以的,就是不够简洁
data = {"Tom": 100,"Joe": 90.5}
def basis(x):
return x[1]
# 输出跟上面的例子一样
for i in sorted(data.items(),key=basis,reverse=True):
print(i)
这样,我们就能更加看清此出key参数的用法了。
若是字典按值求最大最小项,也是一样的道理
data = {"Tom": 100,"Joe": 90.5}
print(max(data.items(),key=lambda x: x[1])) # >>> ('Tom',100)
字典的键
当某种数据作为字典的键存在时,他就必须满足一些条件,这一点不像字典的值,可以是任意对象。键要满足的条件必须满足以下两条规律
1. 键必须是“唯一”的
每个键只能对应唯一的值,也就是说过不会存在两个相同的键对应不同的值的情况。换个角度理解,也就是说字典中的每一个键都是唯一的,不存在和他相同的键
(1) 键冲突
当字典中的键发生冲突时(出现了相同的键),取最近的一次为准
a = {"A": 1,"A": 3} # 键'A'冲突了
# 以最后一次键值对的关系为准
print(a) # >>> {'A': 3,'B':2}
需要注意的是,如果作为键的两个对象值相等,就会认为这两个键是冲突的,即便他们是不同的类型。比如整型数字1和浮点型数字1.0
(2) 键值对的更新
其实,上面我在说字典的更新时,也提到过修改一个键所对应的值的方法就是重新对键关联值
a = {"A": 1,"A": 3}
a["A"] = 3
print(a) # >>> {'A': 3,'B':2}
2. 键必须是可哈希的
“可哈希”的概念现在不用过分纠结,你需要掌握的就是一点:键值得是原子型的,不可变的。比如整型,浮点型,字符串,元组等都可以作为键。而像列表,字典这种类型则不能作为键。
需要注意的是,若将元组作为键,则一定要保证元组中的元素也都是可哈希的,也就是说,键元组中不能出现列表这种数据类型。我在上一篇博文中也说过,元组中的元素若是有列表这种类型,则会“可变”(Python–元组)
a = {(1,[2,3]): "first",(2,[3,4]): "second"} # Wrong!
上面这种写法将元组作为键,同时,在元组中又出现了列表元素,这样会报错。